Updating a block model
Introduction
Currently, when you wish to update the blocks of a block model, you need to hit multiple endpoints to complete the workflow:
- The initial update request.
- An upload of data via
PUT {upload_url}(if required).- This is for uploading the data file associated with the update when necessary.
- This request expects either a Parquet, CSV, or Datamine file in the request body.
- The Advise that the update file has finished uploading endpoint.
- This is used to confirm that an update data file has finished uploading to the server.
- This moves the
job_statusfromPENDING_UPLOADtoQUEUED. - This still needs to be hit even when an update does not require a file upload.
- Polling the job URL.
Initial update request
- This is done via the Start a block model data update endpoint. This is the initial request where the server does a sanity check/validation on what the client is attempting to do.
- The server sends back a
job_url, as well as anupload_url(if required).
columns (Required)
In the body of the request, the columns field is required, which is used to convey which operations you wish BMS to perform on the block model during the update.
"columns": {
"new": [
{
"title": "title",
"data_type": "data_type",
"unit_id": "unit_id"
}
],
"update": ["column_titles"],
"rename": [
{
"new_title": "new_title",
"title": "existing_title"
}
],
"delete": ["column_titles"],
"update_metadata": [
{
"title": "existing_title",
"values": {
"unit_id": "unit_id",
"title": "new_title"
}
}
]
}
The sub-fields of columns (or operations): new, update, rename, delete, update_metadata specify the downstream behaviour during the update workflow and have their own rules. Note that in the example above, all operations have sample values, but only for illustration purposes, as performing all five operations with non-empty values in a single update request is not allowed.
Some general rules/mechanics for all of these fields:
- The reserved system columns including
[i, j, k, x, y, z, dx, dy, dz, version_id]and sub-block index columns cannot be targeted using any of the update operations.- Note for Datamine file imports, this restriction extends to the fields
[IJK, XC, YC, ZC, XINC, YINC, ZINC]. These will be mapped automatically from the file to their BMS equivalents.
- Note for Datamine file imports, this restriction extends to the fields
- Any list of titles provided cannot contain duplicates.
- In all cases, unless specifically stated otherwise, columns that are targeted in one operation cannot be targeted in another. For more details, please see Allowed combinations of
new,update,rename,delete, andupdate_metadata.
new (Required)
If you wish to add one or more columns to the block model, as well as data for the added columns, please be guided by the following:
- You must provide the
titleanddata_typefor the new column, wheredata_typeis a member of theDataTypeenum. - You can optionally provide a
unit_idfor the new column, which should match a supported unit that is returned by the Request a list of units endpoint. - Requires a file upload after the initial request.
- The data types of columns in the uploaded file must match the respective data types provided in
columns -> new[data_type].
update (Required)
If you wish to update data in existing columns, please be guided by the following:
- You must provide a list of
column_titlesthat correspond to already existing columns previously provided innew. [column_titles]cannot contain any duplicates or any system columns.- Requires a file upload after the initial request.
rename (Required)
If you wish to rename one or more existing columns, please be guided by the following:
new_titlecannot already be in use.titlemust already exist.- Does not require a file upload.
delete (Required)
If you wish to delete one or more existing data columns, please be guided by the following:
[column_titles]cannot contain any duplicates or any system columns.- Column titles provided must already exist.
- Does not require a file upload.
update_metadata (Optional)
If you wish to rename and/or update the unit ID for one or more existing columns, please be guided by the following:
title (new_title)cannot already be in use.title (existing_title)must already exist.- Both
title (new_title)andunit_idare optional, and the column property will only be updated if set (i.e. non-null). - If provided,
unit_idshould match a supported unit that is returned by the Request a list of units endpoint. - Does not require a file upload.
comment (Optional)
The comment field enables you to provide additional context or notes regarding the update operation of the block model.
geometry_change (Optional)
For sub-blocked models, you must indicate in the initial update request whether the geometry of the sub-blocks will be changed. If the update will change the sub-blocking by creating or destroying sub-blocks, you must set the request field geometry_change to true, but otherwise, you may omit geometry_change, or set it to false. For more details, please see Updating sub-blocked models.
input_options (Optional)
For new and update operations, the details of the data file for upload can be specified using the optional input_options field.
The options for file_format are parquet (default), csv, or datamine.
All formats support a column_name_mapping.
CSV has the following additional options:
decimal_chardelimiterquote_charskip_rowsskip_rows_after_headers
column_name_mapping (Optional)
When the names of columns in the file differ from the titles you want to give them,
a column_name_mapping connects them together in the update. For example:
File
x,y,z,col1
1,2,3,4
Update request
{
"columns": {
"new": [
{
"title": "column1",
"data_type": "Float64"
}
]
},
"input_options": {
"file_format": "csv",
"column_name_mapping": [
{
"file_column_name": "col1",
"column_title": "column 1"
}
]
}
}
update_type (Optional)
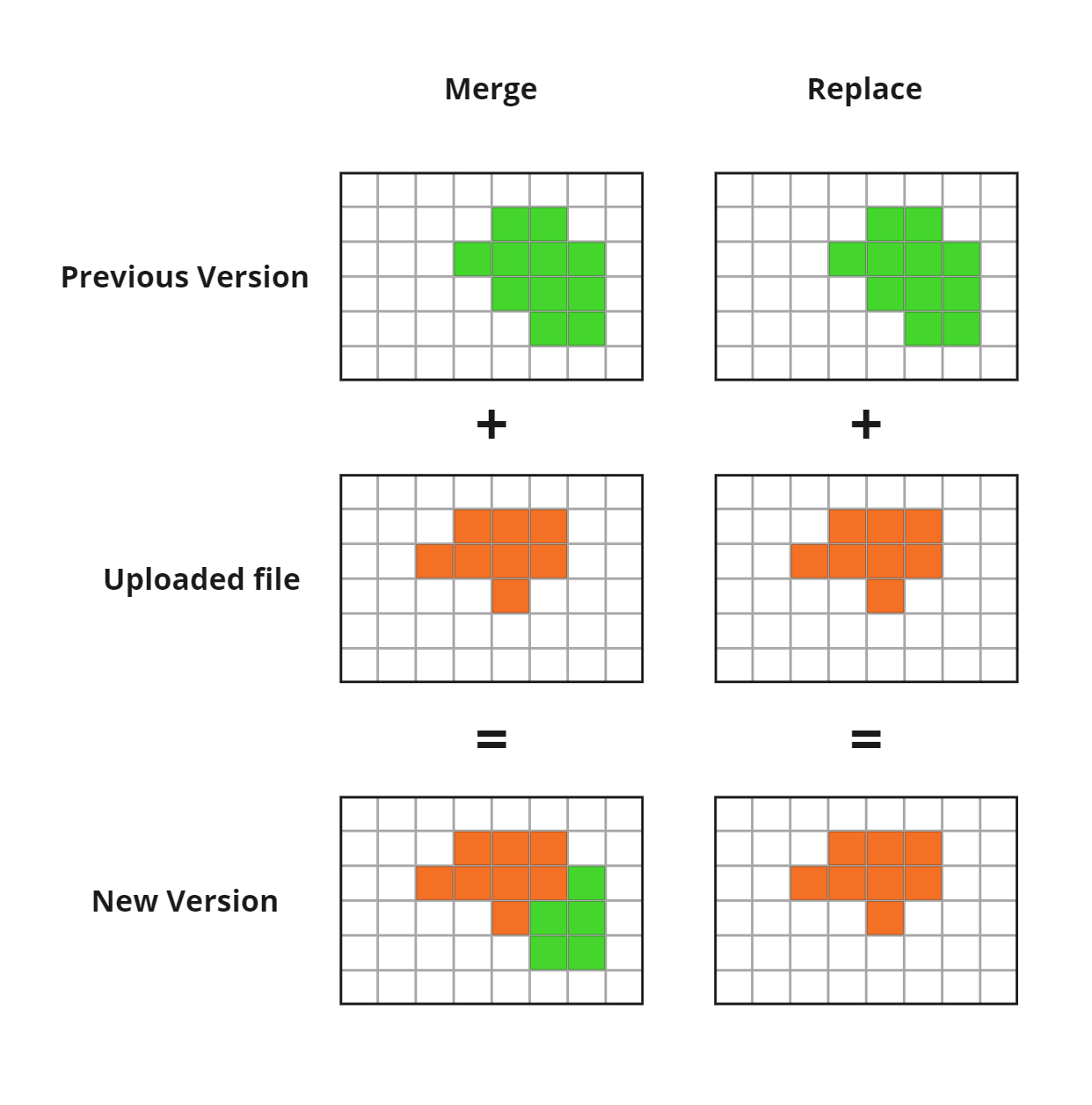
During an update operation, the values in the specified columns for the blocks specified in the uploaded file are
replaced with the new data provided in the same file. The update_type field in the request body specifies how the
update should affect the blocks not in the uploaded file.
- Set
update_typeto replace to set the values for the specified columns to null for the blocks that are absent from the uploaded file. - Set
update_typeto merge (the default) to leave the values for the specified columns unchanged for the blocks that are absent from the uploaded file (the values from the previous version of the block model will be retained).
The below diagram illustrates the effect of the update_type field on the blocks not in the uploaded file.
Details of the columns in the update file
When uploading the data file for the update, the following requirements must be met:
General requirements
- The file must be in either Parquet, CSV, or Datamine format.
- The file must include either IJK (block index) or XYZ (centroid coordinate) information for each block/row, along with the data for the columns specified in the request body, using the correct data type.
- If both IJK and XYZ columns are provided, the service will only use the IJK information.
- Except Datamine which only reads coordinate information, specified with centroids XC, YC, ZC, and block sizes XINC, YINC, ZINC.
Model-specific system columns
The update file must include the required system columns, which vary depending on the block model type. The table below summarizes the required columns for each model type:
| Model type | Required columns | Notes |
|---|---|---|
| Regular | i, j, k or x, y, z | Requires only block indices (i, j, k) or centroid coordinate values (x, y, z). |
| Fully sub-blocked | i, j, k, sidx or x, y, z, dx, dy, dz | Requires additional sub-block index (sidx) or sub-block sizes along the x, y, and z axes (dx, dy, dz). |
| Octree | i, j, k, sidx or x, y, z, dx, dy, dz | Requires additional sub-block index (sidx) or sub-block sizes along the x, y, and z axes (dx, dy, dz). |
| Flexible | i, j, k, start_si, start_sj, start_sk, end_si, end_sj, end_sk or x, y, z, dx, dy, dz | Requires indices of the first (start_si, start_sj, start_sk) and last (end_si, end_sj, end_sk) cells of the sub-block grid, or sub-block sizes along the x, y, and z axes (dx, dy, dz) |
For more details about the system columns for different sub-blocking types, refer to the sub-blocking guide.
Column data type
Each reserved system column must use the correct data type. The table below outlines the required data types for system columns:
| Column | Data type |
|---|---|
i, j, k, sidx | UInt32 |
start_si, start_sj, start_sk, end_si, end_sj, end_sk | UInt8 |
x, y, z, dx, dy, dz | Float64 |
Polling the job URL
After the initial request is successfully processed, the server will return the details of the block model to be created, along with a job_url. The job URL may be periodically polled via the Request job status/result endpoint to monitor the current status of the job until the job_status changes to COMPLETE. Attempting to perform the next operation on the block model before the completion of the current task may lead to errors. The response from the server will vary based on the job_status field, which is further explained below.
Job status: PENDING_UPLOAD
This means that the server is waiting for confirmation that the client has uploaded a file for the update.
Job status: QUEUED or PROCESSING
QUEUED: This means that the update job is currently queued, and will be picked up by the compute service when possible.PROCESSING: This means that the compute service is currently processing the update.
{
"job_status": "QUEUED" | "PROCESSING"
}
Job status: COMPLETE
This means that the update job has successfully completed. The response will also contain the field payload, which will contain the Version object created in the server after a successful update.
{
"job_status": "COMPLETE",
"payload": {
"bm_uuid": "745924dd-4007-4175-a4f8-eb99c9838765",
"version_id": 2,
"version_uuid": "c2287af1-0b1d-459c-93a5-d55596d5cbe9",
"base_version_id": 1,
"parent_version_id": 1,
"mapping": {
"columns": [
{
"col_id": "i",
"title": "i",
"data_type": "UInt32"
},
{
"col_id": "j",
"title": "j",
"data_type": "UInt32"
},
{
"col_id": "k",
"title": "k",
"data_type": "UInt32"
},
{
"col_id": "version_id",
"title": "version_id",
"data_type": "UInt32"
},
{
"col_id": "11111111-2222-3333-4444-555555555555",
"title": "Lithology",
"data_type": "Utf8",
"unit_id": "m"
}
]
},
"bbox": {
"i_minmax": {
"min": 0,
"max": 9
},
"j_minmax": {
"min": 0,
"max": 9
},
"k_minmax": {
"min": 0,
"max": 9
}
},
"comment": "Added Lithology column",
"created_by": {
"id": "ed19712e-f420-4003-8e28-8cf0fdf027a8",
"name": "Joe Bloggs",
"email": "joebloggs@example.com"
},
"created_at": "2023-10-29T23:16:24.734543Z"
}
}
Job status: FAILED
This means that the compute service encountered an error during processing. The response will also contain the field payload, which will contain the following:
- A download link to an error file (not meant to be human-readable).
- An error message from the compute service explaining why the update failed. If the failure is due to a 500 error, a support ticket should be raised.
{
"job_status": "FAILED",
"payload": {
"status": 400,
"type": "https://seequent.com/error-codes/block-model-service/job/indexes-update-error",
"title": "Error when calculating block indices",
"detail": "Update file 9af970b9c57d40b49e8011f7ad7af00e contains block errors: 1 blocks with centroid locations not matching the grid (epsilon values are out of tolerance).",
"download_url": "https://example.seequent.com/blocksync/{org_id}/9af970b9c57d40b49e8011f7ad7af00e.error?{additional_blob_query_params}"
}
}
Allowed combinations of new, update, rename, delete, and update_metadata
General rules
- You may provide the
new,update,delete, andupdate_metadataoperations in a single request, whilst you can only providerenameby itself. If you providerenamewith any of the other operations, a 422 response will be sent back to the client. - You may provide
update_metadataalong withnew,update, anddelete, but only when there are no columns being renamed (i.e. when only the unit ID is being updated). - When either
newand/orupdateis involved in the operation, you must include the columns provided in thenewand/orupdateoperations inside the update data file. - When performing
updatealongsideupdate_metadata, the columns inupdate_metadatamust intersect with columns inupdateifgeometry_changeis true, but can be mutually exclusive otherwise. - When performing
newalongsidedelete, the titles can intersect, since thedeleteoperation will free up names for new columns. - When performing more than two operations at a time, all of the above rules still apply, in addition to:
- The columns in
updateand(new, delete)must be mutually exclusive. - If you are changing the unit ID for a column
update_metadata, the same column cannot be referenced innewordelete, but is allowed forupdate.
- The columns in
Combinations of operations
The table below is an illustration of the allowed combinations when there are two column operations in a single update request.
new | update | rename | delete | update_metadata (unit ID only) | |
|---|---|---|---|---|---|
new | - | ⚠️ | ❌ | ✅ | ⚠️ |
update | ⚠️ | - | ❌ | ⚠️ | ✅ |
rename | ❌ | ❌ | - | ❌ | ❌ |
delete | ✅ | ⚠️ | ❌ | - | ⚠️ |
update_metadata (unit ID only) | ⚠️ | ✅ | ❌ | ⚠️ | - |
where:
| Legend | Description |
|---|---|
| ✅ | Allowed for both intersecting and mutually exclusive columns. |
| ⚠️ | Only allowed for mutually exclusive columns. |
| ❌ | Not allowed. |