Reporting Jobs and Results
Reporting Jobs
Starting a Reporting Job
To apply a Report Specification to a particular block model version and generate a result, a Reporting Job can be created in one of three ways:
- Set the optional
run_nowquery parameter totruewhen creating or updating a Report Specification. When you setrun_nowtotrue(it defaults tofalse), a Reporting Job is created for the new revision. The Reporting Job is run against the latest version of the block model. The URL for the job will be returned in the response, in thejob_urlproperty. - Request the creation of a Reporting Job via a
POSTto the Run a Reporting Job endpoint. - If the
autorunflag is set, a Reporting Job will be automatically run in the background whenever a new block model version is published.
Running a Reporting Job
You can make a request to run a Reporting Job for the current Report Specification against the block model by making a POST request to the Run a Reporting Job endpoint. The body can optionally include a version_uuid indicating the version to run against.
{
"version_uuid": "dd49712e-f420-4003-8e28-8cf0fdf027a8"
}
If you do not set a version_uuid, the job will run against the latest version of the block model.
The service will validate the Report Specification against the selected version, to check that the required columns are present, with appropriate units configured where required. If the selected version is not the latest, and any column used in the report does not have a unit_id set, the unit_id from the latest version will be used (and a warning added to the result, indicating that this has happened).
The response will include the job_url property for querying the status of the Reporting Job. Note that if a Reporting Job is requested for a block model version and Report Specification revision that matches an existing in-progress or completed job, the existing job's job_url will be returned rather than creating a new job.
Reporting Job life cycle
A Reporting Job represents the compute activity of querying the block model data and compiling the Report Results. The job_url can be polled via a GET request to retrieve the current status of the Reporting Job. The server's response is largely determined by the value of the job_status field.
Job status: QUEUED or PROCESSING
QUEUED. This means that the job is currently queued and waiting to be picked up for processing.PROCESSING. This means that a compute node is currently processing the job.
{
"job_status": "QUEUED" | "PROCESSING"
}
Job status: COMPLETE
The means that the job has finished and the Report Result is available.
{
"job_status": "COMPLETE",
"payload": {
"bm_uuid": "aa19712e-f420-4003-8e28-8cf0fdf027a8",
"report_result_uuid": "bb29712e-f420-4003-8e28-8cf0fdf027a8",
"report_specification_uuid": "cc39712e-f420-4003-8e28-8cf0fdf027a8",
"version_uuid": "dd49712e-f420-4003-8e28-8cf0fdf027a8",
"version_id": 3,
}
}
The result can be fetched from the Get a Report Result endpoint, using the report_result_uuid in payload.
Job status: FAILED
This means that the job failed during processing. If the failure is due to a 500 error, a support ticket should be raised.
{
"job_status": "FAILED",
"payload": {
"status": 500,
"title": "Internal Service Error",
"detail": "A service error occurred when processing this job",
"type": "https://seequent.com/error-codes/block-model-service/compute-service-error"
}
}
Report Results
Listing Report Results
List the summaries of the available results for completed Reporting Jobs for a given Report Specification with the List Report Results for a Report Specification endpoint. This endpoint will return all results for the current revision of the specification. The results will be ordered by creation time (newest first). Results for older revisions are retained and can still be retrieved via the Get a Report Result endpoint.
Getting a Report Result
The Get a Report Result endpoint provides the full details of the result, including the following sections:
categories: This provides information on the category columns used in the report. For each category, thelabelandcol_idis provided.value_columns: This provides information on the value columns output in the report. For each, thelabel,col_id, and outputunit_idis provided. The first two entries are for the system-calculated columns Volume and Mass, whosecol_idwill be null.result_sets: These are the result sets for each cut-off value.warnings: This provides information on any warning conditions encountered, including handling of null and negative values in the data.referenced_columns: This provides the details of the columns referenced by ID in the results, including theirtitle,data_type, andunit_idused. If theunit_idwas filled from the latest version during job creation,unit_id_from_versionwill be set to theversion_uuidof the version used.
Rounding and precision in results
The internal calculations performed by the reporting system use 64-bit (also known as "double precision") floating point arithmetic. As is the case with all floating point arithmetic, slight rounding errors are to be expected due to the way values are stored. Reporting values are expected to be accurate to at least 12 significant figures (one part in a trillion).
The exact value of the rounding error for a given set of data can vary slightly between runs, as parallel processing of the data may result in calculations being performed in different orders.
Result sets
The result_sets list contains a result set for each cut-off value requested, in ascending order. If no cut-off is requested, the list will contain a single entry, with a cutoff_value of null.
Each result set has a list of rows, each representing the calculated results for a category value, plus a "Totals" row, as described in the Categories section. Each row contains the following:
categories: The category value(s) that this row is calculated for. The values correspond to the columns described in thecategorieslist.values: The calculated values for thevalue_columnsbased on the aggregation used, and the source and output units.
System-calculated columns
The reporting engine automatically calculates two columns for each row, which are added to the output report:
- Volume: This is the total volume of the blocks included in this row. This will currently always be in m³; unit conversion will be automatically applied for block models with a
size_unit_idother thanm. Block volumes will be automatically adjusted for sub-blocks. - Mass: This is the total mass of the blocks included in this row, based on their volumes and densities. This will be in the requested
mass_unit_id.
Category values
When grouping blocks based on category values, the following rules are used:
- For UTF-8 columns, whitespace is trimmed from the start and end of each value.
- For UTF-8 columns, length is truncated to 1000 characters (after trimming). If any value exceeds this, a warning will be included.
- Grouping is case-insensitive. For UTF-8 columns, output category values will use Title Case.
nullvalues will be grouped as empty strings, regardless of the column'sdata_type.
For "Totals" rows, the total category value will be null.
For each result set, a maximum of 100 category rows will be returned (plus the "Totals" row). If the number of category values seen exceeded this, a warning will be included.
Negative and null values in cut-off and value columns
The Report Specification has two properties for controlling how reporting treats negative and null values when encountered in columns used for the cut-off or for value calculations:
negative_values_policyIGNORE_BLOCK: Using this value will exclude blocks that have negatives in any relevant column (default behaviour)USE: Using this value will use negative values as they are.ZERO: Using this value will treat any negative values as 0.
null_values_policyIGNORE_BLOCK: Using this value will exclude blocks that have nulls in any relevant column (default behaviour)ZERO: Using this value will treat any null values as 0.
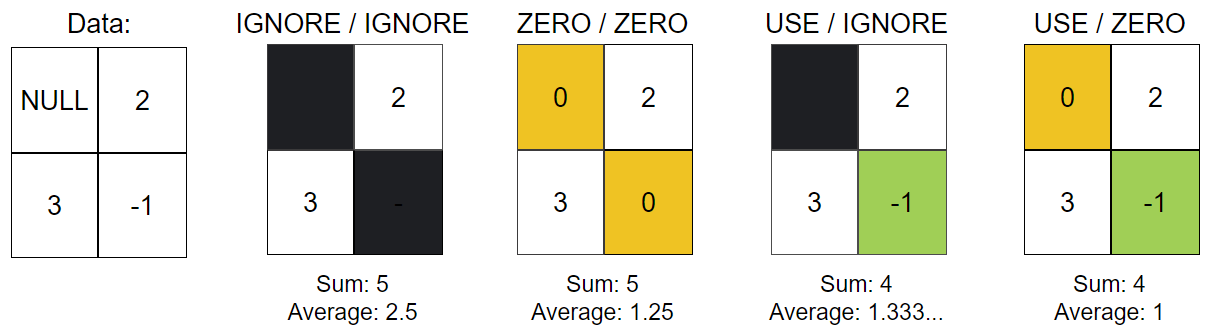
Above: Examples of the effect of combinations of negative and null policies on calculations
Missing sub-blocks
In sub-blocked models, there can be situations where a parent block has some sub-blocks defined, but the rest of the parent block's volume is undefined - i.e. there are 'missing sub-blocks'. In this case, reporting will treat the missing volume as having column values of null, and apply the null_values_policy for the cut-off and value columns.
Warnings
The warnings list provides information on a number of conditions that might be encountered during report generation. Each entry has the following details:
type: The type of the warning.occurrences: The number of times the warning condition occurred. The specific meaning depends on the type.message: A text warning message.
| Type | Description | Occurrences |
|---|---|---|
INVALID_DENSITY_VALUE | A null, negative, or 0 density value was found, and no default was provided. | Number of blocks with issue |
NULL_CUTOFF_VALUE | A null cut-off column value was found. | Number of blocks with issue |
NEGATIVE_CUTOFF_VALUE | A negative cut-off column value was found, and a policy other than USE is in force. | Number of blocks with issue |
NULL_CATEGORY_VALUE | A null category column value was found. | Number of blocks with issue |
NULL_COLUMN_VALUE | A null value column value was found. | Number of blocks with issue |
NEGATIVE_COLUMN_VALUE | A negative value column value was found, and a policy other than USE is in force. | Number of blocks with issue |
TOO_MANY_CATEGORY_VALUES | The total number of category rows exceeded 100, and was limited. | Number of result sets for which this occurred |
LONG_CATEGORY_VALUE | A category value was longer than 1000 characters after trimming, and was truncated. | Number of blocks with issue |
UNIT_FROM_LATEST_VERSION | A column's unit_id was null, and so was filled from the latest version. | Number of columns with issue |